This is a follow up to a previous post we wrote in the midst of our Python 2 to 3 project, describing our strategy and rollout plan. Now that we’ve fully rolled out to Python 3 (as of early September), we wanted to talk about how our production deployment went and reflect a little on the project.
To summarize our approach to this project (as described in the previous post), we established three important guidelines early on: zero downtime, minimal developer disruption, and minimal customer disruption (e.g. as few production bugs as possible). These guidelines were based on the impact that downtime and bugs have to our customers, and the size and frequency of deploys of our web application. Disruption to our developers is quite expensive and we strived to minimize how much they would need to be involved in the project.
This led us to decide to use a small, dedicated team of engineers working almost full time on this project. We established a four-phase approach to the upgrade to ensure simultaneous Python 2 and 3 compatibility during our phased rollout:
- Upgrade all third-party dependencies to a Python 3 compatible version.
- Uplift the syntax of the web application to be compatible with both Python 2 and 3.
- Get the unit test suite passing in both Python 2 and 3.
- Rollout Python 3 to production.
In this post we’ll talk about how each phase went and more importantly what we learned about managing large projects at Rover.
Dependency Upgrades
It took us about 5 months to upgrade our more than 200+ dependencies to a Python 3 compatible version. Our previous post discussed our strategy, so I won’t rehash it here: but this was actually the most time consuming phase of the project. Dependency upgrades are inherently dangerous. Unit tests will typically mock out third party interfaces so you can’t rely on them to ensure functionality is still intact after you upgrade a dependency, especially if that dependency is used in many places throughout the codebase.
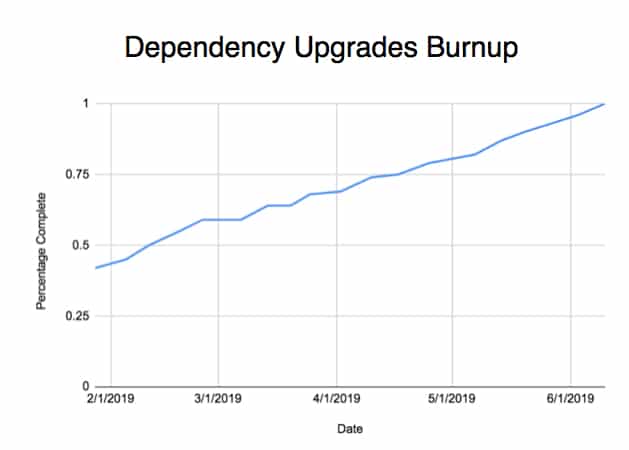
A burnup chart showing the percentage of dependencies on a Python 3 compatible version
Furthermore, many of our features lacked well-defined documentation on how to test them, or smoke tests to sanity check that they were still working. Our small team of engineers often found themselves having to engage with teams who were more familiar with the features to understand how to test them. We were able to upgrade most dependencies without too many issues, but this did require more involvement from other developers than we originally intended.
We learned from this phase that having clear delineation of ownership, well-documented features, and someone who knows how to test them is important to manage risky changes with potentially wide impact.
Support Open Source
We had another perhaps less intuitive discovery from this phase. While you usually don’t want to reinvent the wheel, it’s sometimes less maintenance cost to develop code in-house than to take a dependency on a package. A lot of organizations have a tendency to rely on open-source packages for huge swaths of critical functionality. That’s great, but when you have issues with those packages, it’s important to temper your frustration and recognize that open source maintainers are typically not getting paid and don’t have any obligation to address issues on any sort of service level agreement basis. In cases where you have issues, the best action is to contribute to the package or support the maintainer.
Syntax Uplift
In parallel with our dependency upgrades, we worked on uplifting the syntax of the Rover web application so that it would be simultaneously compatible with both Python 2 and Python 3. This was a prerequisite to begin working on getting the unit test suite passing in both versions of Python.
There are a lot of great tools out there to automate this process. We chose to use python-future, which provides a tool called futurize. The basic idea was to “futurize” a chunk of code, and then update our continuous integration to ensure that any future changes to that code would be compatible with both Python 2 and Python 3. We talked about some of the issues with this approach in the previous post. We struggled finding an efficient way to split up our application’s code base into manageable chunks to futurize.
We ended up choosing “Django application” which is basically a subdirectory within our full web application. However, code is not evenly distributed across these applications, with about 50% of the codebase living in largest 10% of applications. We chose application because it was very simple to enforce in our continuous integration, but it probably wasn’t the best choice given our codebase structure.
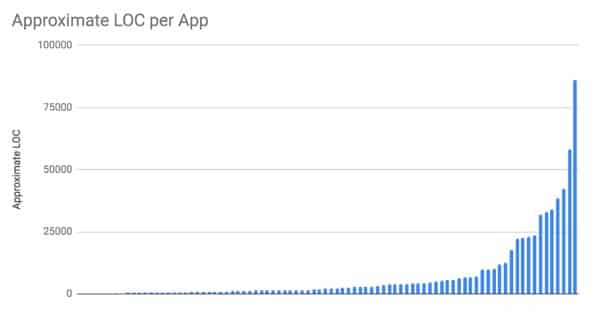
Approximate lines of code per Django application
A better approach may have been to carve out isolated blocks of code that shared functionality and tackle them independently. But this is difficult unless the code is already well-modularized. Our codebase tends to have tight-coupling and cross dependencies which makes this challenging. We also ran into a similar issue as we did with the dependency upgrades: if we don’t have clear ownership of features or good definitions of how to test them, how do we know that things are still working after shipping a large change? We also faced code review fatigue with some of our larger applications because the automated tool generates patches which contain a very similar set of changes over many files.
Our syntax uplift was completed near the beginning of June 2019, and we managed to avoid any major outages despite these challenges. Thus at the beginning of Seattle’s bright and cheerful summer, we began perhaps the most challenging phase of the project: getting our unit test suite passing in both versions of Python.
Unit Tests
We have a very comprehensive test suite with well over 40,000 unit tests. About 2500 of them were failing in Python 3 after our work in the first two phases. This phase was the most important to execute quickly, because once all unit tests were fixed we could start running the full test suite in both Python 2 and 3 in our pull requests to ensure no functional regressions were introduced as we prepared for the production rollout.
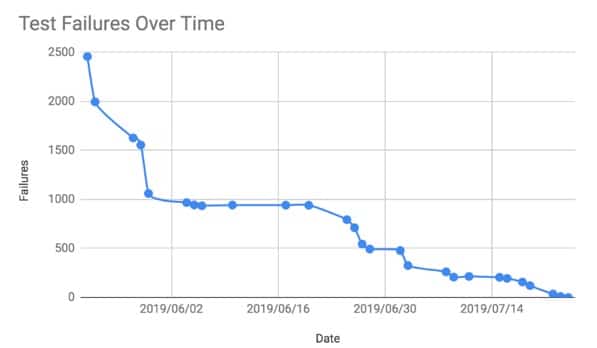
Unit test failures in Python 3 over time
As you can see it took us approximately a month and a half with 2-3 developers working full time to fix all our unit tests to work in both versions of Python. You can see the drops at the beginning as common issues were identified and large swaths of unit tests were fixed, followed by a longer tail of fixing individual test cases.
We made extensive use of our continuous integration (we use Buildkite) to measure our progress and ensure that ongoing changes didn’t introduce regressions by running the test suite in Python 3 every day. Many test failures were due to a few common issues, and most of them were actually due to unit test code rather than production code. By tracking these common issues and communicating closely within our small team we were able to burn through the unit test fixes rather quickly.
Tests are Code, Too
We spent much of our time in this phase fixing test code itself, and we have far more test code than production code. I think it’s easy to forget that test code must be maintained as well, and subconsciously have a lower quality bar for test code than production code.
We also found ourselves learning a lot about our production code by reading through unit tests. Our test suite is extremely comprehensive, but a lot of times the tests might have a different idea about how code should be used than the developers. It’s important that tests accurately reflect the intended use of the code they are testing.
This phase of the project is where we also had some burnout. Blasting through thousands of unit tests in a legacy codebase is tedious work to be focused on full-time, and it’s important to balance the necessity of completing that work with the sanity of your engineers.
Production Rollout
We rolled out Python 3 to one application instance at a time, monitoring for errors, rolling back, fixing them, and repeating. This approach minimized our blast radius and limited impact to our users. One particular challenge I want to call out here was validation prior to our rollout. Our unit test suite is very robust but we have a tendency to over-rely on it. Without equally robust functional or integration tests, and lacking thorough documentation about how to test our numerous features, it took an expensive engineering-wide manual bug bash to ensure that our entire web application was still functional in Python 3.
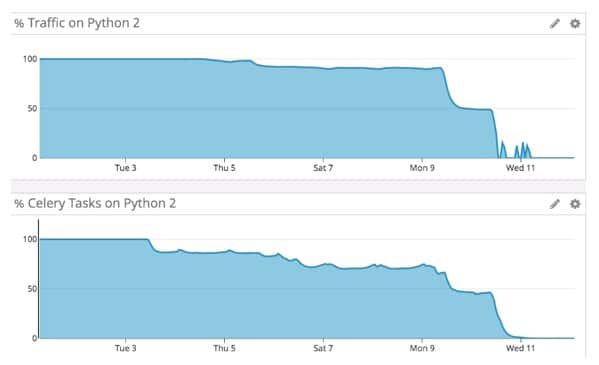
The percentage of web traffic and Celery tasks running on Python 2 over time
The graphs above show our rollout over the first two weeks of September 2019 in terms of the percentage of traffic and Celery tasks on Python 2. The dips correspond to phases of the rollout, with some spikes where we had to rollback and resolve issues.
Project Postmortem
Overall this project went well. We met most of our goals with a minimally disruptive rollout that was technically a few months ahead of schedule, since we finished in September 2019 and end-of-life for Python 2 was January 1st 2020. Most issues involved incompatibilities in the Celery framework between running both versions of Python simultaneously, which means the worst impact was just delayed processing of tasks. Our robust unit test suite caught most issues before they would impact production. However we learned that unit tests aren’t enough, and functional testing is important to cover integrations that unit tests cannot.
There’s been a trend lately away from what we might call “operations” and having full-stack engineers manage infrastructure as well. While I think it’s positive to have engineers more involved in the operations side of things and be “production owners”, we have an awesome infrastructure engineering team who helped establish the best practices and patterns for doing phased production rollouts and I’m really grateful we had access to that expertise. Going forward, we always opt towards making wide-reaching changes slowly and in a controlled manner to limit the potential impact to our users. It’s absolutely worth the additional upfront effort, especially as your engineering organization grows.
Final Thoughts
One of our areas of focus in the next year is on application architecture. A code base with tightly-coupled modules and leaky abstractions makes large projects particularly difficult. I don’t think this is an inevitable consequence of monolithic codebases, but it does make it easy to introduce these sorts of patterns if you’re not careful.
We also missed an opportunity for engineer growth based on the makeup of the team we used for this project. We had a handful of senior engineers working on this project. A better approach would have been to include more junior engineers as an opportunity for them to learn about our codebase and get some feedback about where we can make improvements to our application architecture from folks who may not be as familiar with it. Aligning team composition and the work that needs to be completed for a project is important to maximize not just our ability to finish a project quickly but also to take advantage of potential opportunities for growth of the engineering team.
We’ve had a recurring theme that defining “feature ownership” is a lot harder than it might seem. Validating widely impacting changes is challenging without clear delineations of feature ownership and dedicated QA. I’m excited that we hired a QA manager whose role will encompass helping us manage validation of these sorts of changes and maybe lead to more refined definitions of feature ownership. I think the nature of this “ownership definition” challenge evolves as the engineering organization grows, and being at least constantly aware of it is important to keeping everyone engaged and aligned with what your team is trying to accomplish.
Finally I want to say thank you to all the wonderful folks at Rover who helped assist in this rollout. Without an amazing team this project would not have been possible!