At Rover, we use Elasticsearch as an important part of our search infrastructure. Elasticsearch is a powerful, scalable, and feature-rich search backend which provides many options for fine-tuning the scores of matched documents.
At some point, though, you may grow beyond Elasticsearch’s built-in features for scoring and will want to customize the search scores in more complex ways. For this, Elasticsearch provides script_score, the ability to write scripts to adjust search scores. We’ll talk about how to do that with Painless, a scripting language designed for exactly this purpose by the Elasticsearch team, generally replacing both Lucene Expressions and Groovy scripts in our search backend.
Motivation
We’ve all been there. You’ve got data indexed into Elasticsearch, you have a search score computed, and now you need to adjust that search score in a complex way that depends on runtime parameters such as the user’s location. We’ll go through the process of doing that with the Painless scripting language. A common example of this is a decay curve — a way of decaying a search score according to well-defined mathematical rule. Although Elasticsearch does have support for decay functions) built-in, we’re going to re-implement one in Painless to serve as a starting point for building your own custom decay curves and other score modifiers.
Before we can get into the implementation, however, we’ll need to talk a about what precisely we’ll be implementing. To do this we will look at a few example use-cases and then a discussion of Gaussian decay.
Examples
- A user is searching for dog sitters near their home. They’d prefer a dog sitter closer to home, but a really good sitter that’s just a little further away would be a good fit as well. This is a good candidate for Gaussian decay.
- A user is looking for recent and popular posts on a forum as determined by upvotes, but a slightly older post that’s exceptionally popular should still show up higher on the list. You could just show all the popular posts within the last day, but that is a somewhat arbitrary cutoff. It may be preferable to determine the post’s popularity based on when it received upvotes and reduce (decay) the score based on the age of those upvotes. This is a good candidate for exponential decay for real-time updates after you’ve already indexed the computed score. Evan Miller has discussed the general idea of this algorithm.
- A customer has an idea of how much they want to pay for a good or service, but rather than filtering by specific price ranges you want to show everything and reduce the scores of the services that are too far away from the price range the user wants to pay.
In all of these cases we have a document, a score on that document, and we want to decay that score based on some kind of distance. Distance is used here in the mathematical sense of a “distance function” — geospatial distance, distance in time, distance between two numbers (like money), etc. For my fellow math nerds, we’re formally talking about a semimetric.
Gaussian Decay
Since I like dogs and this is, after all, Rover, let’s use the dog sitter example from above. We’ll implement our Painless script to modify the field search_score using a Gaussian function. We use Gaussian decay because of its bell shape: it starts and ends very gradually, with a steeper reduction in the middle. It is defined almost identically to the standard Gaussian function:

The parameters are defined as follows:
location- The document’s location (in our case, a GeoPoint, though it could be the document’s creation-date or a service’s cost)
origin- The thing we’re measuring distance from.
location - originis our particular document’s distance. offset- A parameter that allows us to preserve a document’s score at 100% of its original score for a little while. For instance, we might choose not to decay the score at all for the first mile.
sigma,- This value is computed such that the score is decayed by
decayamount at distancescale:
For example, if
decay=0.6andscale=2 milesthen we will decay search scores to 60% of their original value when the dog sitter is 2 miles away from the searcher’s home.
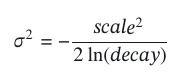
Putting it all together
Sample Data
Here’s the Python script I used to generate the results for the below queries. You may have to pip install names requests. It will create an index called decay_score_example and a type called sitters with three properties: location, name, and search_score. It will also index several records within a few miles of the Space Needle in Seattle. Adjust ELASTICSEARCH_INDEX to suit your testing environment.
#!/usr/bin/env python
import json
import random
import names
import requests
ELASTICSEARCH_INDEX = 'http://192.168.99.100:9200/decay_score_example'
def create_index():
mapping = {
"mappings": {
"sitters": {
"properties": {
"location": {"type": "geo_point"},
"name": {"type": "text"},
"search_score": {"type": "double"}
}
}
}
}
response = requests.put(ELASTICSEARCH_INDEX, json.dumps(mapping))
response.raise_for_status()
def create_sitters():
center_lat = 47.620492
center_lon = -122.349304
for i in range(100):
sitter = {
'name': names.get_full_name(),
'search_score': max(0, random.normalvariate(100, 20)),
'location': {
'lat': center_lat + random.normalvariate(0, 0.1),
'lon': center_lon + random.normalvariate(0, 0.1),
},
}
response = requests.put('{}/sitters/{}'.format(ELASTICSEARCH_INDEX, i), json.dumps(sitter))
response.raise_for_status()
if __name__ == '__main__':
random.seed(1234)
create_index()
create_sitters()
script_score basics
Although there are many features offered by Elasticsearch’s function_score, our relatively simple use-case will only call for a single script_score. script_score‘s script accepts a few parameters: a language (Painless), params to pass in (which allows the backend to avoid recompiling when parameters change), and inline (the script itself). The documentation contains much more information.
Let’s start with the most basic script — sort by distance. In Painless we can get the distance between a document’s GeoPoint field and a fixed center point by doc['location'].planeDistance(params.center_lat, params.center_lon). I’ll go with Seattle’s Space Needle as my center point:
POST /decay_score_example/sitters/_search
{
"query": {
"function_score": {
"functions": [
{
"script_score": {
"script": {
"lang": "painless",
"params": {
"center_lat": 47.620492,
"center_lon": -122.349304
},
"inline": "doc['location'].planeDistance(params.center_lat, params.center_lon)/1609.34"
}
}
}
]
}
},
"sort": [
{
"_score": "asc"
}
]
}
What’s with that magic constant 1609.34, you ask? planeDistance() returns distances in meters, and this is the number of meters per mile.
Note that in this specific example I’m using an ascending sort order since we want sitters who are closer to our center location to show up first.
Here’s the partial response:
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 100,
"max_score": null,
"hits": [
{
"_index": "decay_score_example",
"_type": "sitters",
"_id": "90",
"_score": 0.83584535,
"_source": {
"location": {
"lat": 47.62494347818018,
"lon": -122.3326150097351
},
"name": "Brendan Hembree",
"search_score": 76.11944636262524
},
"sort": [
0.83584535
]
},
{
"_index": "decay_score_example",
"_type": "sitters",
"_id": "65",
"_score": 0.98588717,
"_source": {
"location": {
"lat": 47.610365049386886,
"lon": -122.36421581210658
},
"name": "Debbie Gray",
"search_score": 92.79712125199224
},
"sort": [
0.98588717
]
},
{
"_index": "decay_score_example",
"_type": "sitters",
"_id": "23",
"_score": 1.2417243,
"_source": {
"location": {
"lat": 47.635507642040466,
"lon": -122.36395617407605
},
"name": "Lupe Pena",
"search_score": 116.30107223035154
},
"sort": [
1.2417243
]
},
...
]
}
}
The decay function
Next, let’s build on this to create the the decay function itself. We still won’t be decaying the score, but we can see what the decay function values look like. I’m going to choose a scale of 5 and decay of 0.5 and no offset — meaning that someone who is 5 miles away from the center (the Space Needle) of my search will have their score multiplied by 0.5.
In Painless, as in Groovy and Java, we access many math functions on the Math object.
POST /decay_score_example/sitters/_search
{
"query": {
"function_score": {
"functions": [
{
"script_score": {
"script": {
"lang": "painless",
"params": {
"offset": 0,
"decay": 0.5,
"scale": 5,
"center_lat": 47.620492,
"center_lon": -122.349304
},
"inline": "double distance = doc['location'].planeDistance(params.center_lat, params.center_lon)/1609.34; double two_sigma_squared = -2 * Math.pow(params.scale, 2) / (2*Math.log(params.decay)); return Math.exp(-Math.pow(Math.max(distance - params.offset, 0), 2) / two_sigma_squared);"
}
}
}
]
}
}
}
That script is a little hard to read, so here it is one line at a time:
double distance = doc['location'].planeDistance(params.center_lat, params.center_lon) / 1609.34; double two_sigma_squared = -2 * Math.pow(params.scale, 2) / (2*Math.log(params.decay)); return Math.exp(-Math.pow(Math.max(distance - params.offset, 0), 2) / two_sigma_squared);
Here is a partial response:
{
"took": 11,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 100,
"max_score": 0.98081607,
"hits": [
{
"_index": "decay_score_example",
"_type": "sitters",
"_id": "90",
"_score": 0.98081607,
"_source": {
"location": {
"lat": 47.62494347818018,
"lon": -122.3326150097351
},
"name": "Brendan Hembree",
"search_score": 76.11944636262524
}
},
{
"_index": "decay_score_example",
"_type": "sitters",
"_id": "65",
"_score": 0.973411,
"_source": {
"location": {
"lat": 47.610365049386886,
"lon": -122.36421581210658
},
"name": "Debbie Gray",
"search_score": 92.79712125199224
}
},
{
"_index": "decay_score_example",
"_type": "sitters",
"_id": "23",
"_score": 0.9581509,
"_source": {
"location": {
"lat": 47.635507642040466,
"lon": -122.36395617407605
},
"name": "Lupe Pena",
"search_score": 116.30107223035154
}
},
...
]
}
}
The final implementation
The only thing to add now is multiplying by the document’s search_score. In Painless, we access this value simply with doc['search_score'].value, and it’s a small tweak to scale the search score by the decay:
POST /decay_score_example/sitters/_search
{
"query": {
"function_score": {
"functions": [
{
"script_score": {
"script": {
"lang": "painless",
"params": {
"offset": 0,
"decay": 0.5,
"scale": 5,
"center_lat": 47.620492,
"center_lon": -122.349304
},
"inline": "double distance = doc['location'].planeDistance(params.center_lat, params.center_lon)/1609.34; double two_sigma_squared = -2 * Math.pow(params.scale, 2) / (2*Math.log(params.decay)); return doc['search_score'].value * Math.exp(-Math.pow(Math.max(distance - params.offset, 0), 2) / two_sigma_squared);"
}
}
}
]
}
}
}
The only change here was to the final line of the script:
double distance = doc['location'].planeDistance(params.center_lat, params.center_lon) / 1609.34; double two_sigma_squared = -2 * Math.pow(params.scale, 2) / (2*Math.log(params.decay)); return doc['search_score'].value * Math.exp(-Math.pow(Math.max(distance - params.offset, 0), 2) / two_sigma_squared);
And here is the final partial response:
{
"took": 18,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 100,
"max_score": 135.8321,
"hits": [
{
"_index": "decay_score_example",
"_type": "sitters",
"_id": "49",
"_score": 135.8321,
"_source": {
"location": {
"lat": 47.63852316345303,
"lon": -122.3374752555735
},
"name": "Steven Williamson",
"search_score": 143.00279393048535
}
},
{
"_index": "decay_score_example",
"_type": "sitters",
"_id": "23",
"_score": 111.43398,
"_source": {
"location": {
"lat": 47.635507642040466,
"lon": -122.36395617407605
},
"name": "Lupe Pena",
"search_score": 116.30107223035154
}
},
{
"_index": "decay_score_example",
"_type": "sitters",
"_id": "91",
"_score": 108.21249,
"_source": {
"location": {
"lat": 47.60770098312408,
"lon": -122.38554803898226
},
"name": "Stephen Mason",
"search_score": 119.67356503695572
}
},
...
]
}
}
What next?
Elasticsearch supports Gaussian decay as a built-in decay function. We used this example to show off the power and simplicity of modifying search scores with Painless, but if all you need is Gaussian decay or another built-in decay function then you should use the functionality provided by Elasticsearch.
On the other hand, this is is just the beginning of what you can do. You can do all sorts of things with Painless that you can’t do with Elasticsearch’s built-ins such as piecewise-defined decays or more complicated operations. You could implement a multivariable logistic regression, chi square distance on histograms, and so much more. Experiment and figure out what works best for you!