In early 2020, we faced a challenge familiar to many engineering teams: critical infrastructure running on end-of-life software. Rover uses Elasticsearch as the backbone of our browse marketplace, the feature that connects millions of pet owners with pet sitters and dog walkers. We were using version 5.6, which reached its end of life (EOL) in Q1 2019. In order to ensure we continue to receive security updates and have access to new functionality, we needed to upgrade to a supported version.
This effort involved multiple major version upgrades, a complete rewrite of our search infrastructure, a critical decision about competing technologies, and a migration between cloud platforms.
Why This Mattered
Running on end-of-life software meant security risks (no patches for newly discovered vulnerabilities), missing features (including Learning to Rank for ML-driven search improvements), and performance limitations. In 2021 we were fortunately able to patch the log4j security vulnerability, which affected Elasticsearch, but there was no guarantee we’d receive a security patch for similar vulnerabilities discovered in the future.
Unfortunately, we couldn’t just click an “upgrade” button. We had a number of architectural dependencies that made this upgrade path anything but straightforward.
The Roadblock: django-haystack
We used to use a third-party library called django-haystack for search queries and indexing. At the time we started this effort, in Q1 2020, this library was no longer in active development, and was blocking our upgrade to a supported version of Elasticsearch.
In order to unblock an upgrade to a supported version of Elasticsearch, we needed to remove django-haystack from the web app. We chose to replace it with Elasticsearch DSL, which is the officially supported high level Python client from Elastic. Using a first-party library instead of something like django-haystack should give us a much stronger guarantee of long-term maintenance, which should help us avoid having to perform a costly client library migration again in the future.
This wasn’t a simple library swap. django-haystack was deeply embedded in our codebase with complex indexing logic and querying (dozens of filters), across a number of critical flows. Because django-haystack uses a fundamentally distinct paradigm to interact with Elasticsearch, this meant that we essentially had to re-build most of our search functionality from the ground up.
Given the breadth of changes required to perform this migration, we followed adhered to Rover’s core value of “Intentional balance of pace and precision” and indexed heavily on precision over pace, to minimize the risk of any outages or bugs:
- Built a new system alongside the old one
- Ran both in parallel with extensive validation
- E.g. Validated that searches using both systems returned the exact same data in production
- Gradually rolled out the new system while maintaining instant rollback capability
Once complete, we were free to upgrade Elasticsearch. 🎉

The First Upgrade: Elasticsearch 6.8
With django-haystack finally out of the picture, we were ready for our first major version upgrade: from 5.6 to 6.8.
Fortunately, the breaking changes were minimal. We needed to:
- Remove the unsupported
include_in_allmapping parameter from our indices - Update our Docker containers and staging environment
- Perform the in-place upgrade on AWS OpenSearch Service
- Upgrade the elasticsearch-dsl library
The staging upgrade went smoothly. Production had a small hiccup.
Learning from the 6.8 Upgrade
While performing the upgrade of our OpenSearch cluster from Elasticsearch 5.6 to Elasticsearch 6.8, we experienced a spike in 5xx errors. It seemed that we ran out of IOPS during the upgrade which ultimately resulted in the errors we were seeing. According to AWS we were under-provisioned. Once we started to see the errors, we didn’t have a straightforward option to resolve them. We simply had to cross our fingers and wait for the upgrade to complete.
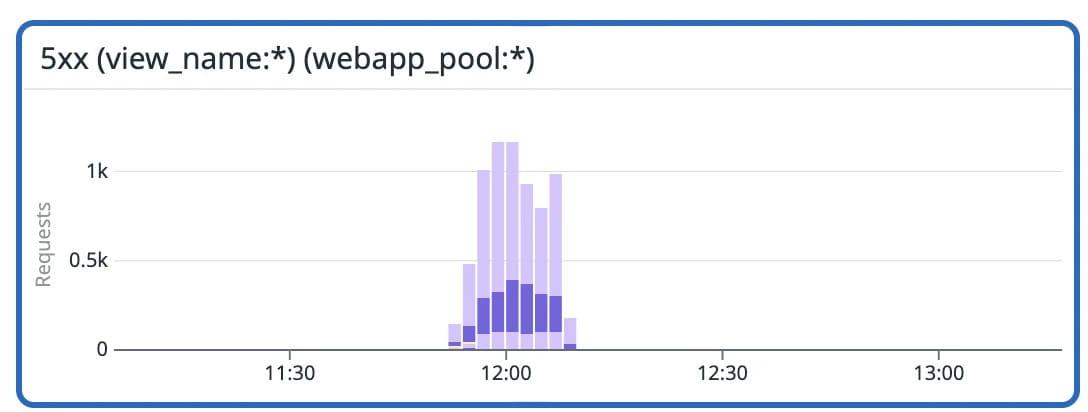
Temporary increase in 5xx errors across endpoints using Elasticsearch
After the upgrade completed, we saw sporadic connection timeouts and elevated master node CPU on the cluster before things eventually stabilized.
Key takeaways:
- In-place upgrades are risky because you can’t easily rollback. We didn’t have the option to stop the upgrade once it started
- What works in staging doesn’t always predict production behavior at scale
Learning from mistakes and a blameless postmortem process are keys part of Rover’s engineering culture. Despite the misstep with the 6.8 upgrade, we were able to identify where we went wrong, and how we could adjust our approach for future upgrades.
Upgrade to 7.10
Learning from 6.8, we took a different approach for the upgrade to 7.10. Instead of an in-place upgrade, we:
- Provisioned a completely separate Elasticsearch 7.10 cluster running alongside our 6.8 cluster
- Implemented dual indexing: Modified our code to write to both clusters simultaneously using feature flags
- Backfilled the new cluster: Reindexed all historical data into the 7.10 cluster
- Validated data consistency: Compared document counts and spot-checked individual documents
- Gradual search traffic migration: Used feature flags to slowly shift read traffic from 6.8 to 7.10
- Monitored extensively: Created rollout dashboards tracking key metrics across both clusters
This approach had a major advantage: instant rollback capability. If we detected any issues with the 7.10 cluster, we could flip a feature flag and immediately route all traffic back to 6.8. No waiting, no complicated rollback procedures.
We similarly maintained instant rollback capability like this with the django-haystack migration. The main difference with the approach we used here is less extensive data validation (no parallel searches). We instead leaned more heavily on monitoring to validate that the upgrade was successful.
We used separate feature flags for writes and reads, allowing us to populate the new cluster without affecting user queries, then gradually shift traffic. The 7.10 rollout went smoothly.
The Fork in the Road: OpenSearch vs. Elasticsearch
We had successfully reached Elasticsearch 7.10, but we hit another roadblock.
In Q1 2021 there was a falling out between AWS and Elastic, which ultimately led to AWS creating a new library, OpenSearch, which is a fork of Elasticsearch. OpenSearch Service allows use of legacy Elasticsearch OSS versions, up until 7.10, at which point you would need to switch to OpenSearch.
This meant that if we wanted to upgrade Elasticsearch past version 7.10 (which is now also EOL), we essentially had two paths:
- Adopt OpenSearch: Migrate from Elasticsearch to the forked OpenSearch project and stay on AWS OpenSearch Service
- Switch platforms: Move to Elastic Cloud (Elastic’s own managed service) and continue with Elasticsearch
After conducting a thorough vendor analysis, we decided to migrate to Elastic Cloud and continue with Elasticsearch. At Rover the majority of our infrastructure is on AWS, so this this was a significant split from the norm for us, which would incur a not-insubstantial migration cost.
Ultimately, the deciding factors ending up being:
- Better Learning to Rank (LTR) support with Elasticsearch 8
- This was a feature that we were very interested in exploring to improve our search relevance with ML models
- Significantly faster development pace and a richer feature set
- Elasticsearch had roughly 4x the number of commits compared to OpenSearch since the fork, which showed in some of the additional features the Elasticsearch provided
- Elasticsearch also seemed to have better community adoption and support
When comparing Elasticsearch and OpenSearch, the majority of the base functionality is limited based on Lucene’s feature set, so we didn’t expect any major differences based on how we use this software today. Looking forward, we saw strong evidence of better long-term support particularly for ML features that we knew we were likely to use in Elasticsearch. This was worth the cost of an infrastructure migration to us.
Migration to Elastic Cloud
The Elastic Cloud migration involved setting up new infrastructure (Terraform provisioning, VPC peering, SSO integration, observability), migrating data through dual indexing and backfill, and gradually cutting over traffic using our (now standard) gradual rollout approach (5% → 10% → 25% → 50% → 100%).
The migration went smoothly thanks to incremental approach and comprehensive monitoring.
Upgrade to 8.17
With our infrastructure now on Elastic Cloud running Elasticsearch 7.10, we were ready for the upgrade to 8.x, the version that would give us access to native Learning to Rank support and other modern features.
Elastic Cloud made this easier than our previous upgrades. The platform’s “Upgrade Assistant” analyzes indices for deprecated features, identifies settings that need changing, provides a guided upgrade path, and performs rolling upgrades with zero downtime.
Two-Step Upgrade
We couldn’t jump directly from 7.10 to 8.17, but we could do it in two steps:
Step 1: 7.10 → 7.17
- A minor-version upgrade that Elastic Cloud could handle with no downtime
- We validated in staging first, confirming no issues
- Production upgrade completed smoothly
Step 2: 7.17 → 8.17
- Used Elastic Cloud’s Upgrade Assistant to identify any issues (showed green across the board)
- Performed a rolling upgrade in production
In both of these cases, we maintained a “Backup Cluster” running on 7.10. All of our application code was configured to be able to read and write to the backup cluster, so we could easily switch traffic over to it, in the event that there were any issues during the upgrades. This guaranteed that we would not have any downtime.
The code changes were minimal. Upgrading our client libraries required more specific type annotations and more granular exception handling, but overall the elasticsearch-dsl API remained stable.
While Elastic Cloud’s Upgrade Assistant flagged most issues, key changes included geoshape field parameters being removed , stricter type checking in elasticsearch-dsl requiring explicit types and specific exception handling, and various cluster-level settings being deprecated or restructured (thread pool settings, node role configuration).
Key Technical Patterns That Worked
Before diving into the lessons learned, let’s talk about what actually worked:
Blue/Green Migration Pattern:
For major version jumps, we stood up new clusters alongside old ones, dual-wrote to both, validated consistency, then gradually migrated read traffic. This gave us instant rollback capability at every stage.
Feature Flag Architecture:
Separate flags for reads and writes meant we could populate new clusters without user-facing risk, then gradually shift query traffic independently.
Comprehensive Monitoring:
We tracked infrastructure metrics (CPU, IOPS, storage), consistency metrics (document count deltas), and business metrics (conversion rates, latency). For each upgrade, we created standard rollout dashboards to spot issues quickly.
Lessons Learned
After multiple major version upgrades and a complete infrastructure overhaul, here are the key lessons we’ve learned:
1. Dependencies Matter More Than You Think
django-haystack seemed like a convenient abstraction when it was chosen years ago. But convenient abstraction layers create a dependency on that abstraction library being maintained alongside the core software. When django-haystack stopped being maintained, we couldn’t upgrade Elasticsearch itself. When evaluating dependencies, consider the maintenance status and community health, and think about your ability to fork or replace the dependency if needed. Official, vendor-supported libraries often provide better long-term stability.
2. Gradual Rollouts Are Worth the Complexity
It’s tempting to simply log into your cloud deployment and click the “Upgrade” button. However, our most successful upgrades used dual clusters and gradual traffic migration. The 6.8 in-place upgrade had a small outage. The tradeoff:
The cost: Running two clusters temporarily (~2x infrastructure cost), additional code complexity, more comprehensive testing.
The value: Zero-downtime migrations, instant rollback (feature flag flip), validation at each step, no risk of being stuck mid-upgrade.
Ultimately the fact that we cannot rollback to previous Elasticsearch versions on a particular deployment makes this worth it. Anything we might have missed during testing would need to be fixed forward.
Feature flags were central to making this work. They allowed us to enable indexing gradually, compare systems without impacting users, roll out to staff first, and instantly rollback when needed. We rolled out gradually (0% → 5% → 10% → 25% → 50% → 100%), pausing at each step to monitor metrics. This caught issues that only appeared under real load before they affected all users.
3. Staging Never Tells the Full Story
The 6.8 upgrade worked perfectly in staging but had issues in production. Even the best staging environments are not one-to-one with production. Scale matters, so always have a production rollback plan.
For many of our upgrades and migrations, we were able to build confidence by shadow testing the new systems in production, after testing in staging. Coupling this with comprehensive monitoring and metrics allowed us to understand how the new system would run in production before it was actually user-facing.
The Outcome
Today, Rover’s search infrastructure runs on Elasticsearch 8.17 on Elastic Cloud. We have security through regular updates, access to modern performance optimizations, native Learning to Rank support, and a proven upgrade process for future versions. We’ve established an service-level objective (SLO) to ensure that we don’t fall more than two minor versions behind in the future, and are currently looking forward to a very near-term upgrade to Elasticsearch 9!
More importantly, we’ve transformed what was once an urgent technical debt problem into a modern, maintainable system. We’ve established patterns and processes that will make future upgrades significantly easier.