Caching is an incredibly effective strategy for realizing performance improvements across common data access patterns. Caching can also be a common source of headache when used ineffectively.
There are only two hard things in Computer Science: cache invalidation and naming things. Phil Karlton
In this article we will deep dive a specific real world case study where we analyzed the effectiveness of implementing a caching layer over an expensive “point-in-polygon” SQL query executed in our Search API layer. This felt like a prime candidate for caching on paper – an expensive query over data that rarely (if ever) changes – but would that cache be effective in practice?
Background
Recently, the Marketplace teams at Rover (the teams responsible for maintaining Rover’s Search platform) have been deeply optimizing our Search APIs to support some new and exciting work happening in the world of Rover Search.
Part of this optimization effort has been identifying common bottlenecks and inefficiencies within our Search API codepaths. One of these inefficiencies was a “point-in-polygon” SQL query executed on every single search.
This “point-in-polygon” query takes the center point of a search event (a lat/lng) and returns data about the geography encompassing that point (such as ZIP code, CBSA, and country code). It does this by determining which, if any, pre-defined geographic polygons this point intersects with.
About Geocoding
Geocoding is the process of converting human-readable location information (such as an address, city name, or postal code) into geographic coordinates (latitude and longitude). These coordinates enable spatial operations like proximity searches, map displays, and distance calculations.
In the scope of the Search API, we use our Geocoder Database to reverse-geocode a set of latitude and longitude coordinates into more human readable data describing the geographic area of the search event. That data is then used throughout the rest of search logic and analytics.
This process is the source of our expensive “point-in-polygon” query. This query, given a set of latitude and longitude coordinates (the “point”), attempts to reverse-geocode that point by querying for its location inside a database of polygon objects representing geographic locations.
Why cache at all?
This point-in-polygon query accounted for nearly 18% of our Search API’s P95 response time – an expensive and valuable block of time.
In general, the geographies associated with a given set of coordinates change exceedingly rarely. Additionally, users tend to search the same general area multiple times when using our platform.
Because these lookups are both repetitive and stable, caching is a natural fit to improve performance and resiliency. However, our search center points used for the reverse-geocoding process include four digits of precision – roughly ~10m accuracy. This level of accuracy has the potential to drive an outsized volume of cache misses as well as bloat the overall size of the cache.
In other words, if our cache key is something like a concatenation of 4-digit precision lat/lng coordinates, this cache will probably underperform. Rather than using points as our cache key, what if we used Geohashes instead?
What is a “Geohash”?
A Geohash is a method of encoding geographic data into a hash. As the length of the hash increases, so does the precision.
For the purposes of our specific use case, we targeted three Geohash lengths for our investigation into cache effectiveness:
- Geohash of length 5 = ~5km spatial accuracy
- Geohash of length 6 = ~1km spatial accuracy
- Geohash of length 7 = ~150m spatial accuracy
Implications of using Geohash over lat/lng
You will note a serious implication of using Geohashes over lat/lng points at the precision we had been using for reverse-geocoding – accuracy.
Where our lat/lng center points were giving us ~10m precision, our longest considered Geohash offers only 150m of spatial accuracy. This means that we will lose some accuracy at the borders of geographies where a point may fall within a Geohash that “straddles” the border of a shape.
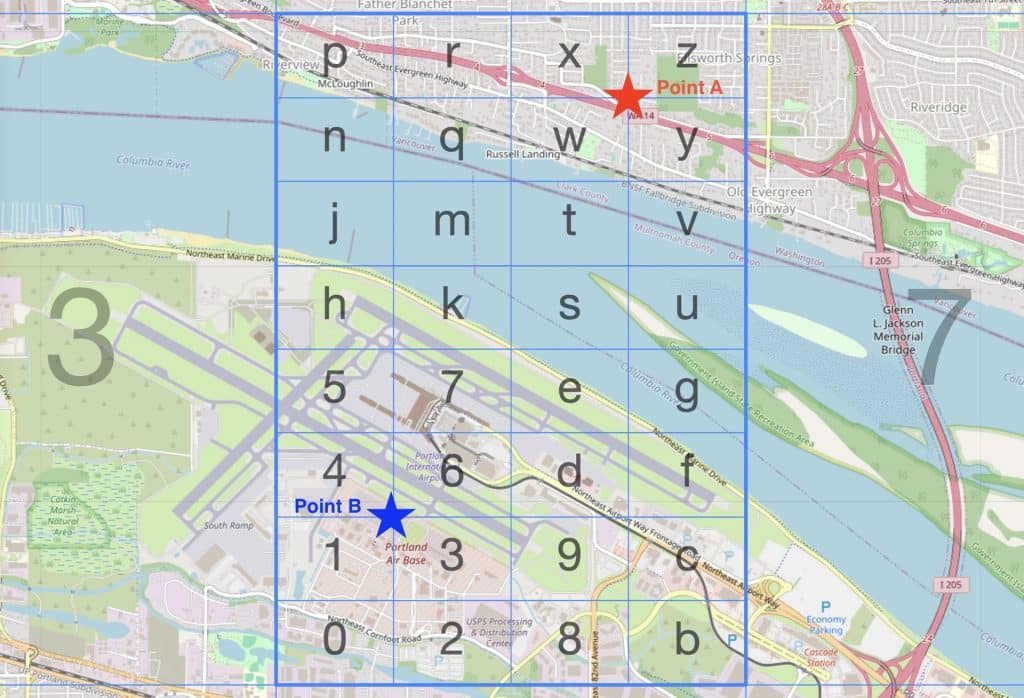
A sample illustration of a Geohash5 that sits across the Oregon and Washington border: Point A falls within Washington, and Point B within Oregon. Both points exist within the Geohash c20g6
This is a tradeoff that it is critical for us to understand, but that we agreed was worth the cost.
Will it be effective?
It was at least clear that effective caching would speed up this reverse-geocoding process, but would caching actually be effective here?
We were concerned that choosing too fine of a cache key resolution (a long Geohash or concatenated lat/lng) would explode cache size and limit effectiveness, as small variations in search location could result in frequent cache misses and low reuse across otherwise nearby searches.
To understand this risk more deeply, we had to investigate how this cache would behave in the real world. Moving forward with Geohashes, we leveraged historical search data in our data warehouse to understand what our estimated cache hit ratios might be, building SQL queries to convert search center points to Geohashes (we opted to look into Geohash6 and Geohash7) and simulating a 7 day cache to evaluate effectiveness.
How it Works
- Filter bad data – We separate invalid coordinates (e.g., 99999, 0,0) to avoid errors. We count all invalid coordinates as cache misses
- Compute Geohashes – For each search event, we encode its center point (lat/lng) into a “Geohash”, which is a short string representing a small area (~1 km)
- Aggregate daily – We count total searches and the number of unique geohash cells per day
- Simulate a 7-day cache – For each day, we look back across the prior 7 days and compare how many lookups hit the same cell versus new cells
- Calculate the estimated hit ratio – Hit Ratio = 1 – ( Distinct Valid Cells / Total Valid + Invalid Requests )
Arguably one of the most important pieces of this simulation is the first bullet above – ensuring that bad data like invalid coordinates is represented as a cache miss. Not accounting for this edge case could dramatically impact the results of our investigation.
Computing Geohashes from our search center points was also made easy with spatial SQL functions available in our Redshift data warehouse – taking our latitude and longitude center points, converting them to a point geometry, then using that point to derive a Geohash.
We could then aggregate these Geohashes and simulate our hit ratio as described above for a 7 day TTL cache. For this data in particular, even a 7 day TTL may be shorter than necessary as geography doesn’t change often.
The Result?
Caching would be effective here! And more effective than we had predicted – Geohash6 simulations suggested a cache hit ratio around 0.8 (80%), while Geohash7 suggested cache hit ratio of 0.78 (78%).
This means that approximately 80% of requests would result in a cache hit, helping us eliminate the time spent hitting the Geocoder Database for the majority of requests. In other words, we can estimate that this efficiency would result in an ~18% improvement to P95 request time for 80% of search requests. For an already fairly optimized API, this performance gain is a huge win.
On cache miss, we simply fall back to the existing database query and populate the cache with the result.
The very minor performance gap between Geohash6 and Geohash7 also came as a surprise. Geohash7 would be preferable over Geohash6 due to the increased precision, somewhat mitigating the risk of inaccuracy at the borders of geographies.
Armed with this information, we could more confidently state the estimated performance benefit of introducing this caching layer, and the tradeoffs that such an architectural decision entailed.
Next Steps
Now that we had the data that we needed to evaluate cache effectiveness, we could take the necessary next steps in our planning process.
Because this is an “architecturally significant” change, we wrote an Architectural Decision Record (ADR) proposing this change and shared it more broadly with the Tech organization to solicit feedback from stakeholders.
Once approved, this ADR fed into our roadmap planning process where we organize next steps (writing an RFC, slotting the work into upcoming sprints, etc.).
Summary
The outcomes here are also very dependent on the shape of user interactions with our platform – less geographic density of user interactions would yield worse results from this exact same solution, while a tighter grouping of user geographies might allow us to use even more precise Geohashes.
Its also important to carefully consider what you are optimizing for with something like a caching solution. When a cache miss is expensive and a cache hit has an outsized benefit, even a 60-80% cache hit rate is impactful. If a cache miss is cheap and a cache lookup is expensive or distributed, you likely want something north of 90%.
When it comes to architectural decisions, there are always many factors to consider and rarely a one-size-fits-all solution. This article describes a very specific caching use case, but the underlying story is one of due diligence. Making a big architectural decision (like implementing a caching layer) should be an informed decision, and diving more deeply into your specific problem space can inform not just if a given solution is viable, but also how you might adjust your approach for further gain.